
Improved Observability
Lately, I've been using Langfuse for observability. The tool is pretty cool to observe your LLM applications, track costs, etc. It even has an evaluation feature, but I wouldn't say that it's as best as the other features. Let's say that I don't think that evaluation is the main goal of Langfuse. Anyway.
While playing around, I was a bit frustrated by the Python SDK. It provides a high level abstraction to track the components of your app (through a decorator) but I don't find this feature to be consistent. Some elements really annoyed me.
One can argue that I should then stick to the low-level API, but it would increase verbosity and code duplication, so I don't think it's a good idea. Good libraries provide good abstractions. LangChain is a perfect counterexample. Perhaps I'll write something about it someday...
The Problem(s)
Default values are not tracked
It only tracks values that are actually passed to the functions/methods. This should at least be something the user could opt-in (or opt-out).
The SDK typing is messy
The SDK doesn't stick to the PEP 561. Thus, all types information are not used by MyPy. I haven't checked other type checkers such as PyRight though. Nonetheless, this is pretty bad.
Besides, it doesn't seem that they will address this issue any time soon (langfuse/langfuse #2169).
The tracing behavior is inconsistent
Or, at least, I feel like they are. Observing a single function/method will lead to a trace, with not so much information, while observing the same function/method from another function/method will lead to an observation (which can have a duration, etc.).
import time
from langfuse.decorators import observe
@observe(name="run", as_type="generation")
def run(model: str = "gpt-4o-mini") -> str:
time.sleep(1.0)
return "<response>"
@observe(name="evaluation")
def evaluate() -> None:
time.sleep(0.5)
@observe(name="main")
def main(model: str = "gpt-4o-mini") -> None:
print(run(model))
evaluate()
if __name__ == "__main__":
run() # create a trace, and bind a generation to it
evaluate() # only create a trace
main() # create a trace, and bind a generation and a span to ittrace.py
As an image is worth a thousand words, here are some screenshots. The main trace makes sense. The evaluation doesn't.
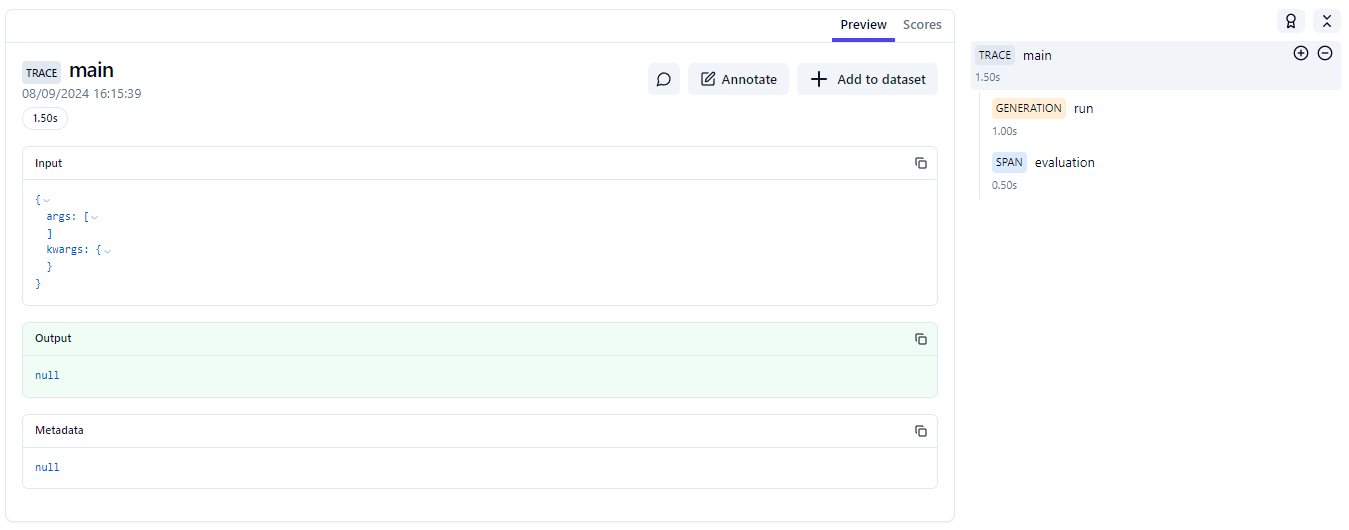
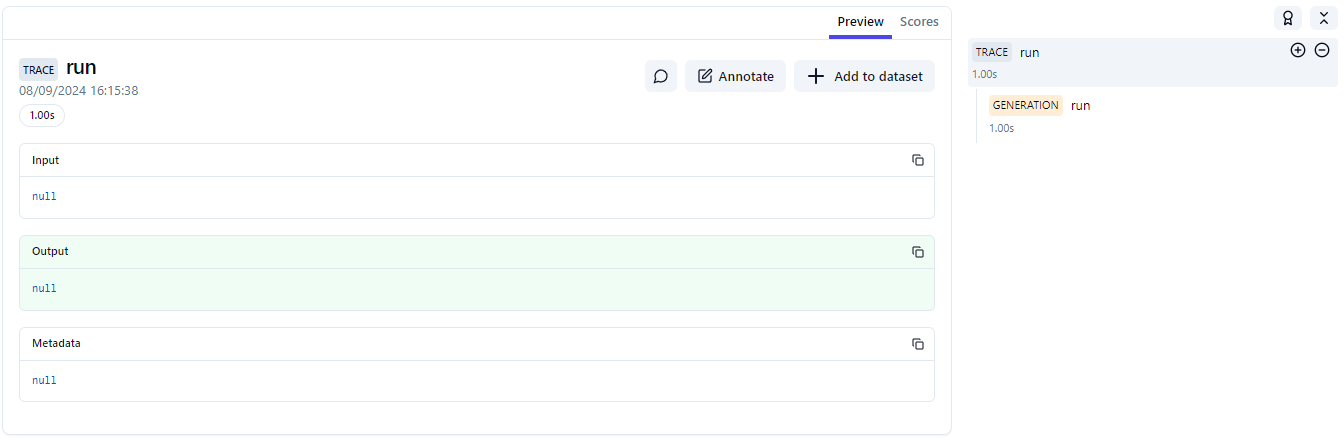
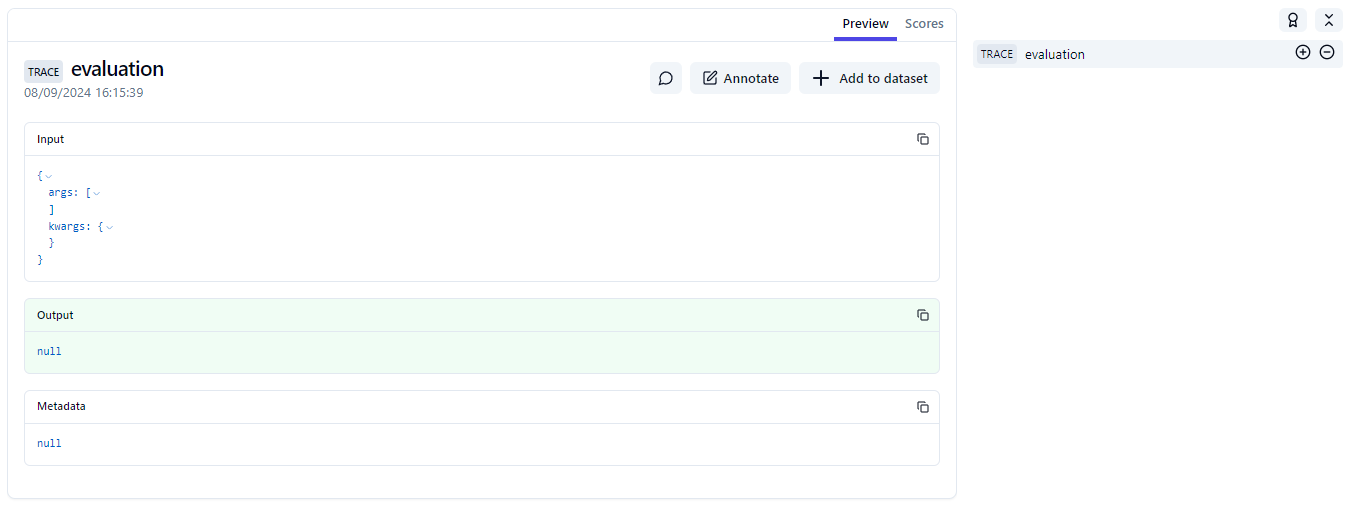
Web views of the different traces with the vanilla decorator
The official documentation states the following about observations :
- Events are the basic building blocks. They are used to track discrete events in a trace.
- Spans represent durations of units of work in a trace.
- Generations are spans used to log generations of AI models. [...]
So I would expect a single span to have a duration, which here is lost. Therefore, I guess the only valid solution would be to create a trace and bind the observation to it every time (unless we're already in a trace of course). This is the current behavior for generations.
The decorator doesn't allow events
This could be consistent. However, I would tend to think that there could be some use cases to consider some function/method calls as events.
No context manager
This is a feature I'd like to have. It would be nice to be able to observe a piece of code. Obviously, we'll lack some data (like the input or output) but that's not a big deal. The user could provide missing data.
The cherry on the cake would be to have the same tool for decoration and context management.
Confusing update mechanism
I find the way they allow the user to update the observation a bit hard to understand. We never know what kind of observation we manipulate, thus we don't know what parameters we should use as they are all exposed.
Details here : langfuse/decorators/langfuse_decorator.py#L716
It's also possible to update the trace. I don't know if it's a good feature or not considering the multiple inconsistencies I'm pointing at.
Rigidity
In my opinion, the way they provide their observability context is really rigid. It uses a singleton internally to get the Langfuse client. Reconfiguring the context will reconfigure the singleton configuration. I've not checked if it's used elsewhere but I think we should give the user a bit more freedom here. Instantiating a client is pretty straight forward (considering that all parameters have defaults).
A Solution
I've been hacking over the weekend to find a more elegant solution to the prior issues. It wasn't that easy but I think that I have a nice first prototype. It hides most of the complexity of the low-level API while keeping a consistent behavior. It also provides the user with a proxy access to the current observation to apply some updates or bind scores. Everything is typed so we always know what we manipulate. Last but not least, it's really simple to use, like the original Langfuse decorator.
I've been criticizing the vanilla decorator but it carries some good ideas, so I inspired myself a bit from it when it made sense. Below is a usage example of this work. One key difference here is that the new decorator injects a proxy argument in the function/method so the user has some freedom to play with.
Under the hood, both the decorator and the context manager share the same code, which is pretty convenient. When updating the proxy, the updates are collected until the function or the context manager exit.
"""Copyright (c) 2024 Bendabir."""
# mypy: allow-any-unimported
# ruff: noqa: D101, D102, D103
from __future__ import annotations
import contextlib
import getpass
import random
import string
import time
from typing import TYPE_CHECKING
from langfuse.client import Langfuse
from trackotron import Observer
from trackotron._version import __version__
from trackotron.updates import GenerationUpdate
if TYPE_CHECKING:
from trackotron.proxies import EventProxyAlias, GenerationProxyAlias, SpanProxyAlias
client = Langfuse()
observer = Observer(
client,
release=__version__,
user=getpass.getuser(),
session="".join(
random.choices(string.ascii_letters + string.digits, k=8) # noqa: S311
),
tags=["dev", "trackotron"],
)
@observer.observe(type_="event")
def error(_proxy: EventProxyAlias) -> None:
raise RuntimeError("Benchmarking.")
@observer.observe(type_="generation")
def generate(
proxy: GenerationProxyAlias,
prompt: str,
*,
model: str = "gpt-4o-mini",
) -> str:
time.sleep(1.0)
output = "This was generated by an AI."
proxy.update(
GenerationUpdate(
model=model,
model_parameters={"MAX_SEQ_LENGTH": 512},
usage={
"input": len(prompt) * 1000,
"output": len(output) * 1000,
"total": (len(prompt) + len(output) + 2) * 1000,
"unit": "TOKENS",
},
)
)
return output
@observer.observe()
def evaluate(proxy: SpanProxyAlias, _output: str) -> bool:
time.sleep(0.5)
proxy.score("perplexity", 1.0, comment="<comment>")
proxy.score("toxic", False) # noqa: FBT003
proxy.score("sentiment", "neutral")
return True
@observer.observe(observation={"version": "test"})
def run(_proxy: SpanProxyAlias) -> str:
with contextlib.suppress(RuntimeError):
error()
output = generate("My super prompt !")
evaluate(output)
with observer.observe(name="example", type_="event") as proxy:
with observer.observe():
time.sleep(0.1)
proxy.score("duration", 0.1)
return output
@observer.observe()
def main(_proxy: SpanProxyAlias, *, _example: bool = True) -> None:
run()
if __name__ == "__main__":
main()demo.py
When possible, the decorator plugs as much information as possible into the trace. By default, it tracks both the input and output (like the vanilla decorator). It also tracks some useful debugging information.
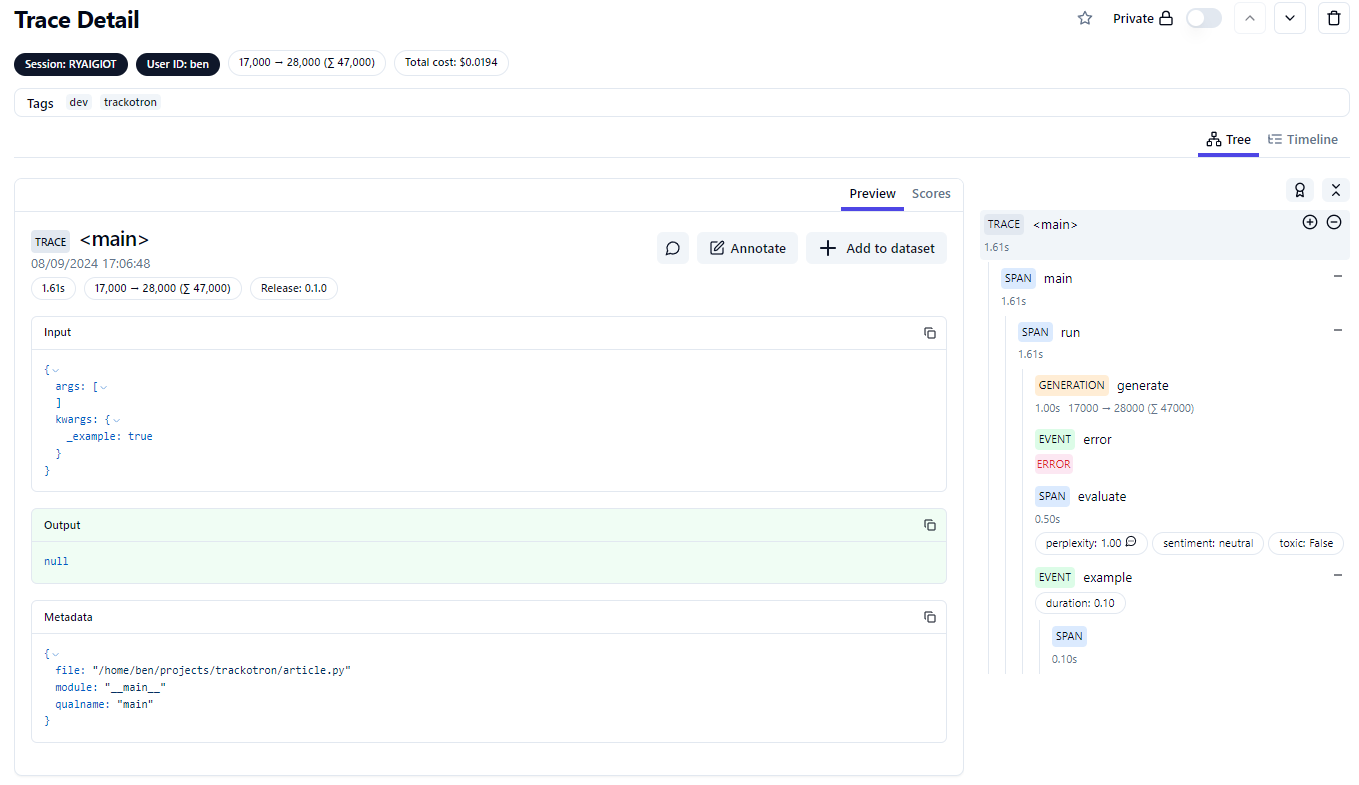
In case of error, it logs a bit more data. I agree that we shouldn't use Langfuse to track errors and logs. There are better tools for that. However, it's pretty convenient to have some details right away. We have to keep in mind that this could cause some security issues as some secrets could be exposed. However, it's not worse than the current tracking mechanism for inputs and outputs.
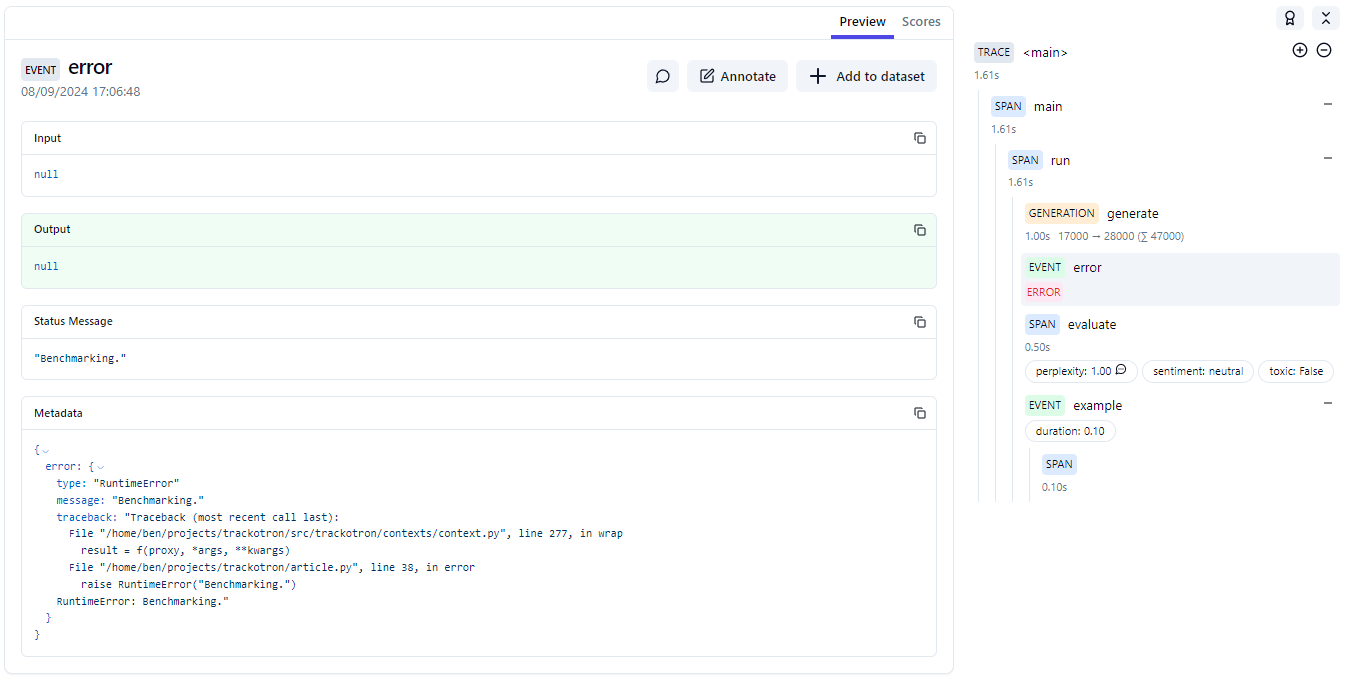
I haven't checked for older versions than 2.45 for the Python SDK. This work remains very experimental and is definitely not production-ready. Please note that Python 3.8 is not supported as it will reach EoL any time soon.
If you're curious, you can check out this work on GitHub.
Limitations
I didn't want to spend too much time on this so there are still some limitations, but I think they can all be fixed quite easily.
The decorator currently only supports functions. MyPy will drive crazy on instance and class methods (despite they should be supported).
Coroutines are not supported yet but it should be pretty straightforward to implement. The only issue is to find a way to avoid code duplication.